Why You Shouldn't Use Claude Code

I barely write code anymore.
I now constantly run a dozen of agents working on a handful of projects. My job shifted from "programmer" to managing a "control plane." It feels very similar to the video games of my childhood; I get buzzing notifications every few seconds, there's a huge amount of context switching. The perfect environment for a generation that struggles to focus on a TikTok without a Subway Surfer video.
But somehow... it works. I have never been so productive.

I spent last year writing software, almost every day. Even when I was wandering in the African jungle I brought a starlink with me to write code. But I did more over the last few weeks than in the past 12 months.
I probably would have been just as effective if I had been on vacation all year and started using Opus just a little earlier.
That made something obvious to me.
Agents are commodities. My workflow isn't.
Agents are a solved problem. We've tested many approaches: creating fleets of LLMs with complex graph architectures to optimize the context passed to each child. Turns out it's not necessary: the optimal design seems to be a simple while loop around an LLM with sufficient time horizon.
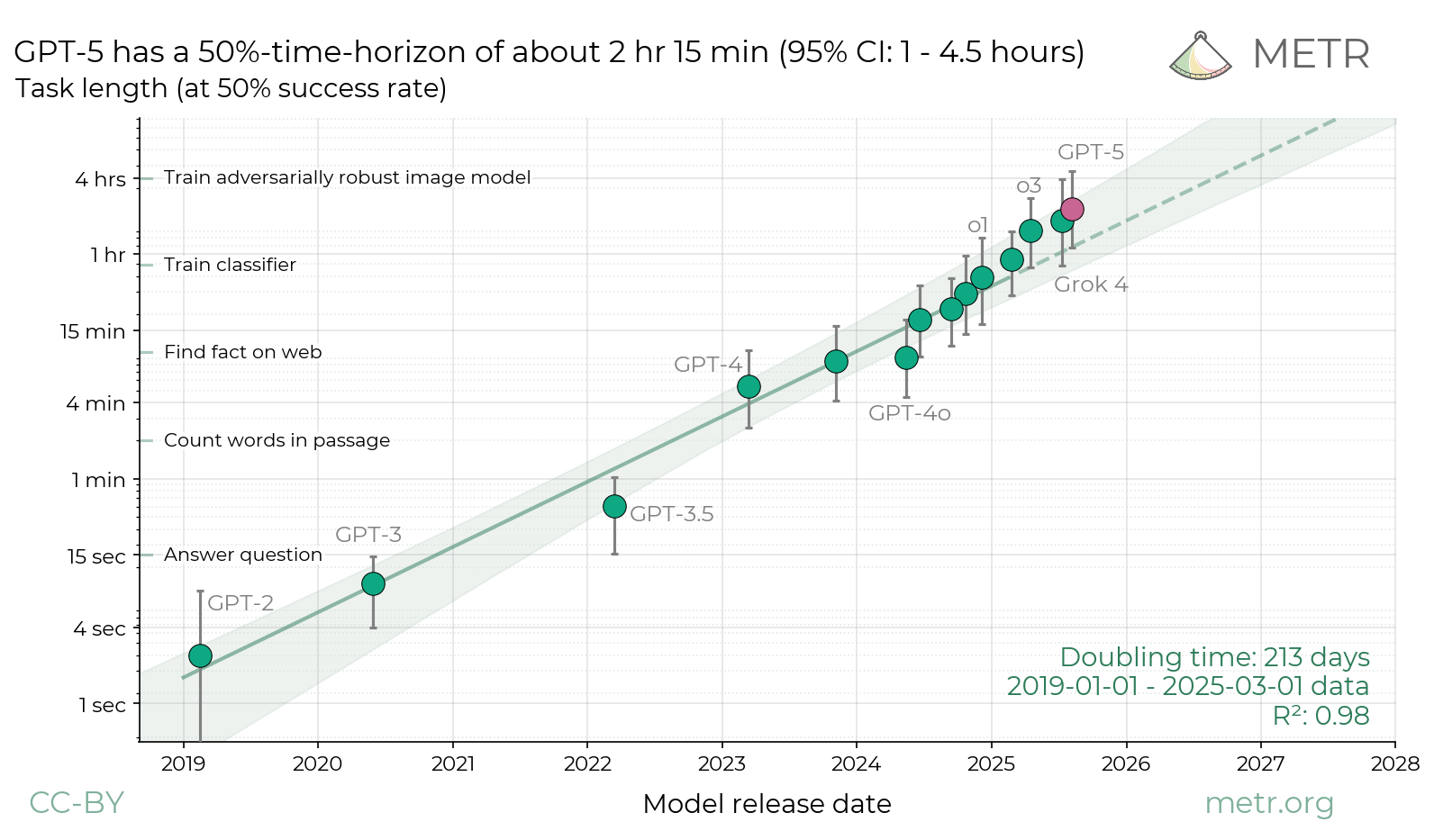
Claude Code, Codex, Cursor agents, OpenCode, whatever comes next, they all converge on the same primitive. Features differ. UX differs. Marketing differs. But structurally, they are the same thing. Which means two things:
- Models will keep making the difference.
- Providers will try to lock you in with their client.
Always having the best models is not a viable long-term strategy for inference providers like Anthropic because it costs them a lot, and once they've made the investments, competitors can replicate the results for less (remember DeepSeek achieving near-GPT performance for a fraction of the price by training on its outputs). So they will try to lock you in.
I believe they will fail.
...And that's why I'm bullish on open source
Writing software is now close to free. The marginal cost of producing code collapsed faster than anyone expected. What matters now is taste. And taste comes from experience.
Open source agent runtimes like Open Code (think a Claude Code clone for any model) will outperform closed ones long-term because taste compounds socially.
Thousands of people:
- trying weird workflows
- stress-testing edge cases
- discovering what actually works at scale
...will always explore a larger design space than any private team can. That's why my top priority now is optimizing for low switching costs. Everywhere.
Imagine if productivity gains continue their current exponential trend, even for a few months. Imagine that Gemini 4 is released and allows me to ship twice as fast as Opus 4.5. Every day spent on Claude Code because I am used to it would have a considerable, increasingly large cost. In the same way as the time spent relearning how to use the best tooling or adapting my config.
You shall be independent
Once I internalized that, I reviewed my entire workflow. Let me break down each layer and what I do to stay flexible.
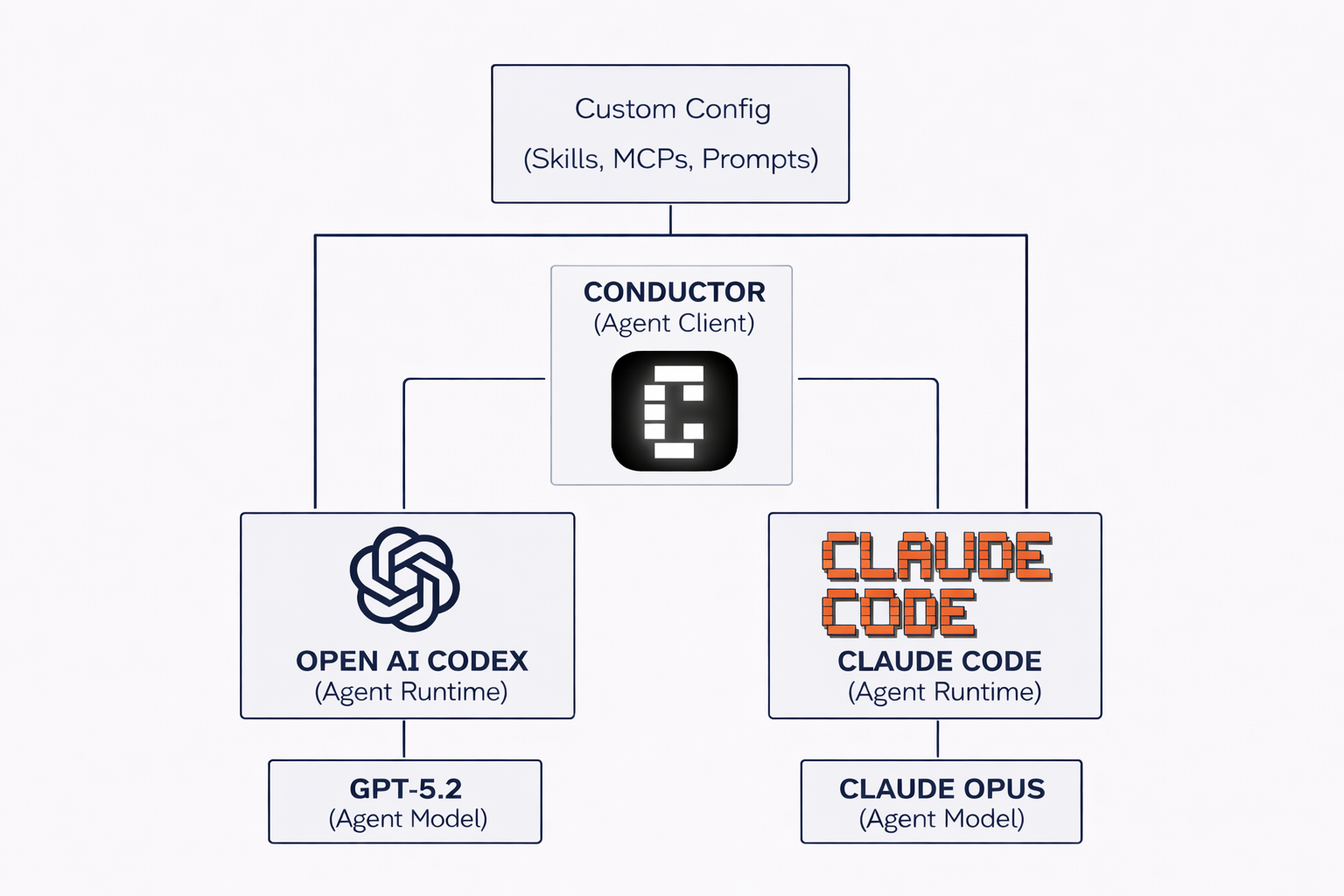
The model (inference)
This is what actually thinks. I constantly switch between Claude, GPT 5.2, and Gemini 3 Pro. When one model gets stuck, another can often solve it with a different approach. The model is a commodity; treat it like one.
The agent runtime
It is the loop that turns a model into something useful. It doesn't matter very much either as long as it supports custom skills, prompts, and MCP configs.
The agent client
This is what you actually interact with and this is where I refuse to use defaults. Claude Code's terminal UI is fine, but it locks you into their ecosystem. I really believe my muscle memory is a liability.
I use Conductor, a native app that can run both Claude Code, Codex, and hopefully soon Open Code or Gemini. Pick what you want as long as you can easily switch the models.
The agent configuration
This is where your taste lives:
- Prompts
- MCP configs
- Skills
- etc
It has a lot of value, and it could be a very strong reason to not move to the best agent available. GPT might be smarter, but if it is blind and can't access your browser, dumb Claude will be better.
Thankfully AGI is here to free us from incompatible standards.
I moved all these configs to a private git repository in my own format, and Claude wrote a script to automatically "translate" and synchronize it with all my agents. If I teach GPT how to reverse engineer Java binaries, Gemini learns it as well.
So what to do next?
Optimizing switching costs gave me some degree of freedom but unfortunately that system is already obsolete. It is poorly suited for long-term tasks and my computer becomes crowded. Sometimes I am reviewing Codex work and Claude bothers me by taking control of my screen. If I leave it running or use a VPS it's particularly annoying to manage remotely (especially from a phone). I'm not even talking about the security risks of giving full access to my machine.
More importantly it still has two huge dependencies:
- First, the inference. 100% of my tokens are produced by US companies. Anthropic blocked OpenCode and is banning third-party client users. New account registration are closed. Cursor requires phone verification. Inference capacity can't keep up with demand and we are one political decision away from losing total access.
- Me. LLMs are, without a doubt, better than me at pretty much everything.
Yet I am still needed, and that doesn't mean I'm useful, it just means I'm doing something wrong.
That's what I'm trying to fix right now. I bought one NVIDIA Superchip before stocks run out and I'm going to learn how to run backup inference.
Regarding the human bottleneck that I am, I started building an infrastructure to control my agents remotely and give them the tools they need to replace me (the ability to control a desktop, launch and test native applications, etc). My mindset is simple: if I can do something, AI can do it better, faster... and cheaper.
Human tokens are not cheap, use them carefully.